
Asynchronous Data Loading - 🏁

As we have learnt in software engineering, optimizing time complexity is vital. More so, managing resources is just as vital. As an MLOps engineer, serving Data Scientists who are utilising multiple data sources; A challenge could be how to pull this data from these disparate sources efficiently.

For instance, a Data Scientist you support is tasked with buidling a machine learning pipeline that uses data sets from different sources. Lets assume:
One of these datasets is from 2021, and the data was stored in-house, in a postgresSQL database (and it has not been migrated since then).
One of the datasets, is from 2022, owned by the FIA, and is stored on Azure (Microsoft Cloud Service).
Another dataset, from 2023, is owned by their organisation and stored on AWS (Amazon Web Services).
A fourth dataset is being streamed from sensors on George Russell’s car, and is hosted on Cassandra.
A fifth dataset is being streamed from Lewis’s race car, and is hosted on Cassandra.
Loading data from each of these sources is likley to take significant amount of time and some datasets will arrive faster than others. Assuming this pipeline is running a GPU instance that is charged per second of processing time, what could you do to optimize the use of this resource? Running asynchronouse functions is one way to makes sure of this.
Asynchronous simply means not occuring at the same time
While loading the data, you may want to run a pre-processing function in the background for each data stream as it is being received. That way, the program would not have to wait for all of the data to have been loaded, before commencing pre-procesing. Hence, the data would not be pre-processed at the same time.
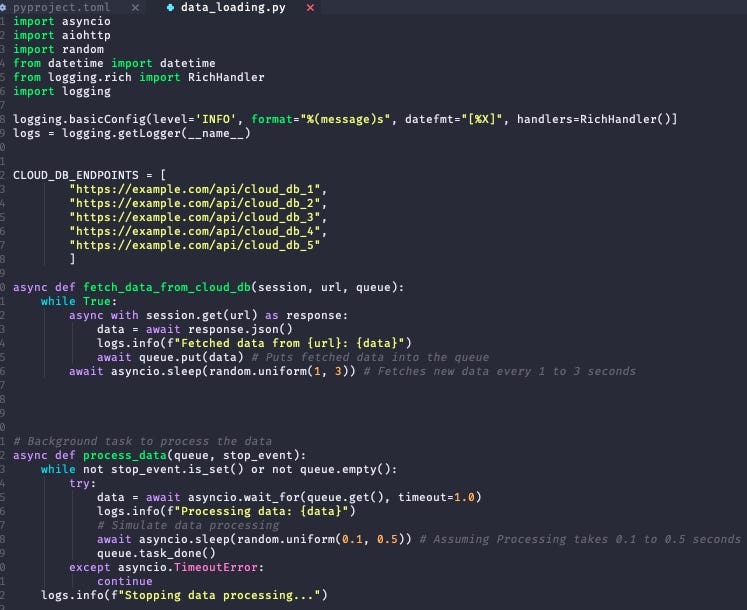
The code snippet above simulates the diverse cloud database endpoints mentioned earlier. The `fetch_data_from_cloud_db`function simulates fetching new data every 1 to 3 seconds. Then the `process_data` function processes the data from the queue in the background. It does this at random intervals between 0.1 to 0.5 seconds. It keeps running till the the `stop_event` is set and the queue is empty.
Finally, the main application sets up the queue, the stop event and creates the data fetching tasks. It simulates running the main application for 20 seconds. Once the application is done running, it then sets the stop_event, signalling the data processing task to stop. It cancels the fetch tasks and waits till all data in queue is fully processed before stopping the data processing task.

This method of handling tasks is also useful with micoservices that call serverless endpoints. During cold starts and request processing, you can set up your application to perform other tasks asynchronously, maximizing time and resource.
I hope you have learnt a thing or two here. If so, please like and share; I will also be happy to answer any questions directly or in the comment section. You can find the source code for the snippets here. You can adapt it for specific use cases.